charset 이란?
문자 집합(charset)은 정보를 표현하기 위한 글자나 기호들의 집합을 정의한 것입니다.
이런 문자나 기호의 집합을 컴퓨터에서 저장하거나 통신에 사용할 목적으로 부호화 하는 것을 문자 인코딩(부호화)이라 하고 인코딩 된 문자 부호(Character code)를 다시 디코딩(복호화)하여 본래 문자나 기호로 표현할 수 있습니다.

그림 1. 대표적인 문자 부호는 모스 부호가 있다
영문 문자 인코딩
영문 알파벳 26자와 숫자, 기호, 특수문자등 128자를 7비트의 이진수로 부호화한 ASCII(American Standard Code for Information Interchange) 부호가 현재도 널리 사용되고 있으며, 실질적인 영문자의 국제 표준 부호입니다.
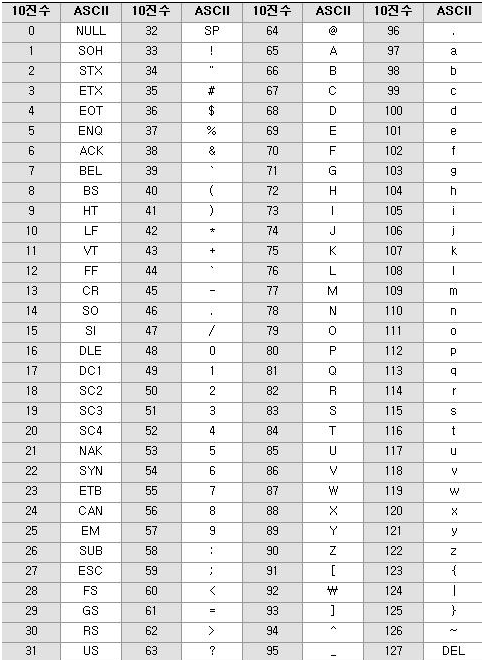
그림 2. 128개의 ASCII 부호
한글 문자 인코딩 역사
한글 문자 인코딩
컴퓨터가 한글을 표현하기 시작하던 1980년대에는 2바이트 조합형 한글을 주로 사용하였습니다. 조합형 한글의 원리는 초, 중, 종성에 해당하는 문자를 각각 부호화하여 문자에 따라 부호를 조합하여 만드는 방식입니다.
그러나 초, 중, 종성을 조합하는 부호표가 각 업체마다 달라서 A사의 컴퓨터에서 작성한 프로그램이 B사의 컴퓨터에서는 한글이 깨지는 문제가 발생하게 됩니다.
정부는 한글 전자 문자 표준의 제정의 필요성을 느끼고 표준을 제정하게 되는데, 당시 학계에서는 조합형 한글이 한글 창제의 원리에 부합하고 모든 활자를 표현 가능하므로 조합형을 표준으로 제안하였으나 정부는 완성형 한글을 표준(KS_C_5601_1987)으로 제정합니다.

그림 3. 한글 문자집합은 총 11172자이다
완성형(KSC5601-87)의 표준 채택 이유
- ISO-2022(2바이트 이상의 문자 부호를 사용할 때 지켜야 하는 확장 방법에 관한 국제 표준)에 따르고 있으므로 외국의 네트워크나 SW 사용에 유리하다.
- 현재의 한글 사용 실태를 조사해 보았을 때 2,350자의 한글만으로도 충분히 모든 표현이 가능하다.
- 정렬 작업에 있어서 한글 변환 테이블을 통해서 가능함으로 크게 문제가 될 것이 없다.
완성형(KSC5601-87)에 대한 반론
- 한글 창제의 원리 초, 중, 종성의 구별이 없는 단순한 부호에 불과하다.
- 모든 한글을 표기 할 수 없으므로 문학 작품을 집필하거나 신조어를 표현할 때 문제가 된다.
- 우리 언어의 영역이 제한 받는 결과를 가져온다.
- 한글이라 붙여진 코드에 한글보다 한자가 더욱 많다. 또한 필요 없는 특수 문자가 너무 많고 외국의 문자집합까지 포함하고 있어 오히려 한글 사용 영역이 줄어들었다.
- 음소의 분석이 어려우므로 형태소 해석이 불가능하여, 차후 음성 인식에서 사용할 수 없는 부호이다.
- ISO-2022를 따르고 있다고 하지만 ISO의 인증은 받지 못한 부호이다.
- 한글 오토마타(automata) 구현에 있어서 한글 키 입력에 의해 조합형 코드가 만들어지면 이를 테이블을 통해 완성형 코드로 변환하여 호출하므로 부담이 된다.
KSC5601이 표준으로 제정되자 기업들은 앞다투어 완성형 한글만을 탑재하기 시작했으나 이로 인해 워드프로세서에서 한글 표기가 제대로 되지 않는 문제(고어나 독음)가 발생하여 워드프로세스의 내부에서 코드를 조합하여 표현이 가능하도록 하는 등의 기형적인 구현사례가 늘어나게 됩니다.
이후 KSC5601-87에 1930자의 한글을 추가한 KSC5657을 발표하였으나 여전히 근본적인 문제가 해결되지 않은 부호로 거의 사용되지 않았고, 결국, 정부는 1992년 기존 KSC5601 완성형과 함께 조합형 한글을 함께 수용할 수 있는 KSC5601-92를 표준으로 제정하여 현재까지 사용하고 있습니다.
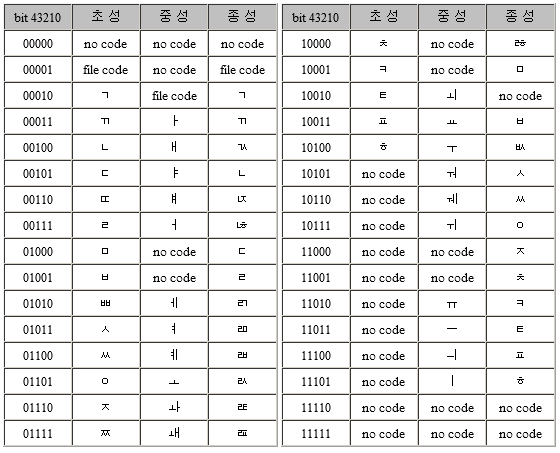
그림4. 2바이트 조합형 한글 부호표 (KSC5601-92)
유니코드(Unicode) 프로젝트
유니코드는 전세계의 모든 문자를 동일하게 표현하기 위한 산업표준으로 유니코드협회(Unicode Consortium)가 제정하며, 유니코드에는 ISO-10646에 포함된 문자집합, 문자 부호화와 문자를 표시하기 위한 복호화 알고리즘이 포함되어 있습니다.
ISO-10646은 문자 표시에 관한 국제 표준으로 초기 ISO-10646과 유니코드는 서로 다른 독자적인 표준이었으나. ISO-10646-1이 제정되면서, ISO실행위원회와 유니코드컨소시엄의 협의로 문자 표시 방법이 통합되어 현재의 국제 표준은 유니코드라고 할 수 있습니다.
(ISO-10646에는 KS X 1001(KSC5601), EUC-KR, ISO-2022-KR의 한글 문자 부호가 포함되어 있다.)
UTF (Unicode Transformation Format)
UTF는 유니코드 형태의 문자를 변환하기 위한 공식이다. 유니코드는 4byte 구성되어 있기 때문에 사용하는 코드 범위에 따라서 1~4byte로 변환이 가능하게 된다. UTF-7, UTF-8, UTF-16BE, UTF-16LE등의 종류가 있다.
EUC
euc는 extend unix code의 약자로 유닉스에서 영어를 제외한 문자를 표시하기 위한 확장 부호를 의미합니다. 그 중 euc-kr은 한글 표현을 위한 문자 인코딩인데, 영문은 KSC5636(ASCII와 동일하나 역슬래쉬를 원표시로 대체)으로 처리하고 한글은 KSC5601로 처리합니다. 과거 euc-kr은 KSC5601-87의 완성형 한글이었으나 현재의 euc-kr은 KSC5601-92로 조합형 한글까지 사용 가능합니다.
CP949
마이크로소프트에서 사용하는 한글 문자의 부호표입니다. 본래 code page는 IBM에서 최초 고안하였으나 MS-window에서 한글 표현을 위해 채용하면서 MS949로 불리우기도 합니다. 처음 CP949는 KSC5601에 표현된 2350자만을 제공하였으나 KSC5601-92가 제정되면서 조합형 한글에 대한 부호표도 추가되어 제공되고 있습니다.
KSC5601 vs EUC-KR vs CP949
KSC5601은 완성형과 조합형의 모든 한글 문자의 표현이 가능한 한글 문자 부호 표준이며 euc-kr과 CP949는 모두 이 KSC5601을 기본으로 한 문자 부호입니다. 유닉스계열의 한글 문자 부호인 euc-kr에서는 KSC5601을 그대로 수용하고 있으며, 윈도우계열 한글 문자 부호인 CP949(MS949)는 완성형 한글의 형태를 취하고 있으나 KSC5601에 의해 조합형으로 만들어지는 한글의 코드까지도 제공하고 있으므로 두 문자 부호의 인코딩 방식은 달라도 같은 코드를 만들어 내게 되어 두 문자 부호는 서로 호환됩니다. 단, java환경에서는 euc-kr이 KSC5601-87로 사용되어 CP949의 확장 완성형과 호환되지 않을 수도 있으니 주의해야 합니다.
KSC5601 vs Unicode
유니코드에는 KSC5601의 문자 집합이 포함되어 있지만, 4byte의 유니코드의 어느 범주에 속하느냐에 따라 그리고 어떤 변환식을 사용하느냐에 따라 부호의 값이 달라지므로 KSC5601을 그대로 사용하는 euc-kr(CP949)와 유니코드는 서로 호환되지 않습니다.
현재의 Charset 요약
유니코드(Unicode)
옛날옛날 컴퓨터가 세상에 나왔을 때는 ‘영어’와 몇가지 ‘특수문자’만 사용했고 이를 저장하기 위해서 1 byte면 충분했다. (0~255) 시간이 흘러 다른 국가 사람들이 컴퓨터를 이용하다보니 자국어도 컴퓨터로 표시하고 싶어졌다. 그래서 1 byte 안에 임의대로 알파벳 대신 자기나라 글자를 할당해서 그럭저럭 쓸 수는 있었다. 그러나 네트워크가 발전하고 다른 사람 홈페이지를 들어갔더니 글자가 와장창 깨지고 만다. 그리하여 국제적으로 전세계 언어를 모두 표시할 수 있는 표준코드를 만들기로 했다. 바로 유니코드(Unicode)다. 참고로, 한글 ‘가’는 유니코드로 ‘U+AC00’이다. 왜 그러냐고 이유는 묻지마라. 약속이다.
유니코드는 글자와 코드가 1:1매핑되어 있는 ‘코드표’이다. (코드표)
UTF-8
유니코드를 통해 코드표가 정의되었다. 남은 것은 그 ‘코드’가 컴퓨터에 어떻게 저장되어야 하는 것이다. 다른 말로 인코딩(encoding)이라고 하는데, 컴퓨터가 이해할 수 있는 형태로 바꿔주는 것이다. 예를 들어, 길동이가 자기만의 암호체계를 만들었는데 ‘가’는 0001(=1)로, ‘나’는 0010(=2)이라고 하자. 길동이가 ‘가나나가’라고 말하면 컴퓨터에는 0001 0010 0010 0001로 저장한다. 글자당 1 byte로 할당해 4 byte로 저장할 수 있고 00010010 00100001처럼 2byte로 저장할 수도 있다. 이건 전적으로 길동이와 컴퓨터간의 약속이다. 길동이만 쓸 때는 문제가 없는데 전세계 사람들이 사용하려면 좀 더 잘 만들어야 할것이다.
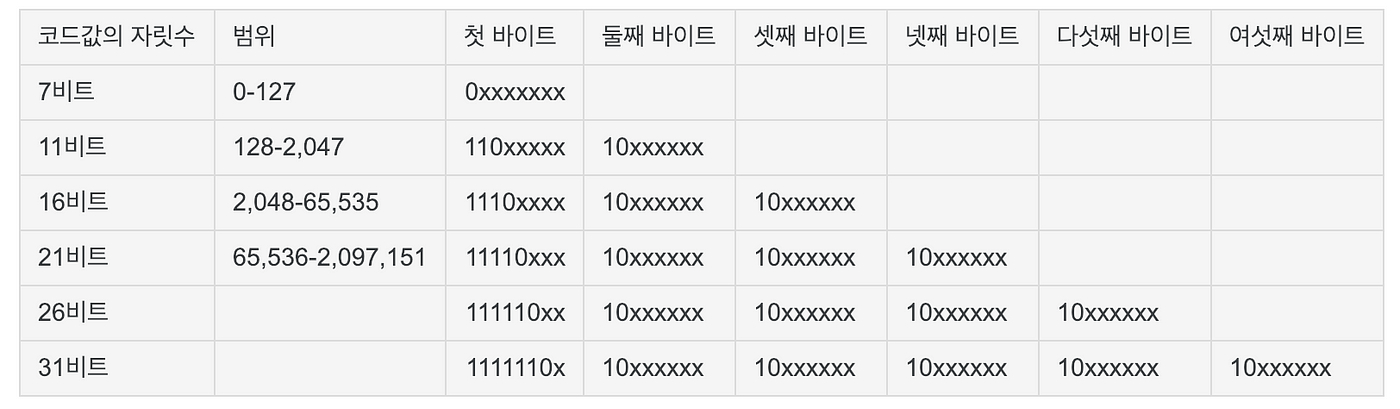
UTF-8은 유니코드를 인코딩(encoding)하는 방식이다. 전세계에서 사용하는 약속이다.
UTF-8은 가변 인코딩방식이다. 쉬운 말로 하면 글자마다 byte 길이가 다르다는 것이다. ‘a’는 1 byte이고 ‘가’는 3 byte이다. 가변을 구분하기 위해 첫 바이트에 표식을 넣었는데 2 byte는 110으로 시작하고 3바이트는 1110으로 시작한다. 나머지 바이트는 10으로 시작한다. 왜 그러냐고 묻는다면, 그냥 ‘약속이다’라고 말하고 싶다.
댓글
댓글 쓰기